챗GPT 3.5 버전에서 나타나는 환각 현상을 줄이기 위해 RAG를 간단하게 만들어 봤다. langchain을 이용해서 답변을 개선하는 방법을 테스트해봤다. (colab에서 작업하다가 jupyter로 옮겼다. 계속 노트북이 멈추는 문제가 생겨서... colab 이나 주피터나 사용 방법은 대동소이 하기 때문에 크게 어렵지 않다고 생각함.)
Anaconda에서 jupyter 사용하는 방법 영상: https://youtu.be/1oQCRniWDy0?si=8pPRJFG9RK6lBUzK
Jupyter 사용 방법: https://youtu.be/NJaZuqt839I?si=dgFA5T5LTIkB2G4W
langchain에서 openAI API를 사용하기 위한 라이브러리를 먼저 설치해주고 테스트해봤다.
저번 포스팅부터 테스트하고 있는 조선왕조실록 세종대왕 기록에 대한 논란으로 계속 환각을 테스트해보고 있다.
아래와 같이 gpt-3.5에서는 계속 부정확한 썰을 풀려고 노력하는 것을 볼 수 있다.
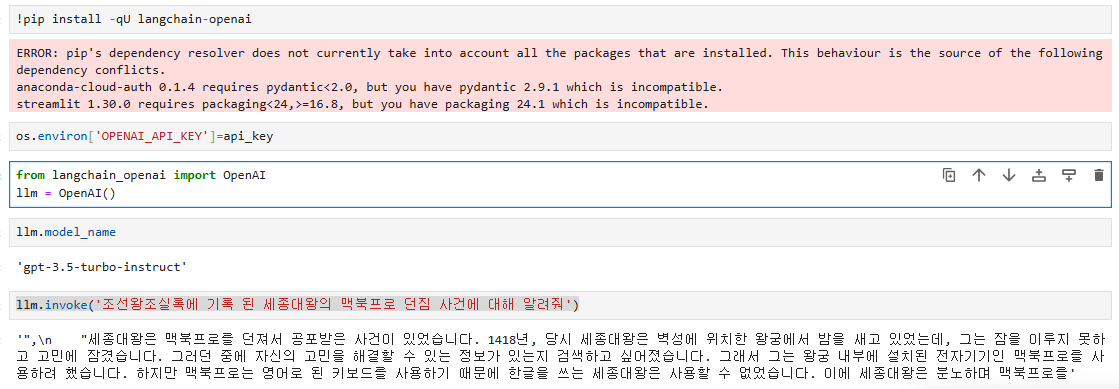
gpt-4에서도 환각이 일어나는지 확인해봤는데, gpt-4는 환각을 잘 피해갔다. gpt-4를 사용해보려고 이것저것 시도해보다가 결국 코파일럿 도움으로 코드를 찾았다. OpenAI에 직접 gpt-4 모델명을 입력했으나 자꾸 에러가 발생해서,ChatOpenAI로 사용을 했다.
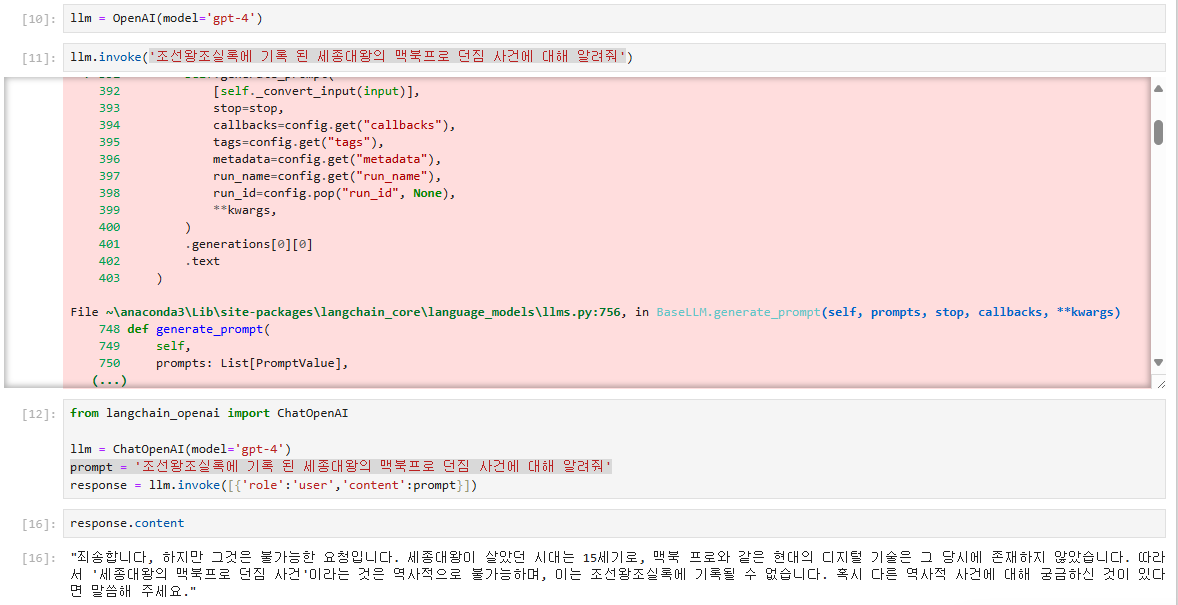
처음 아이디어는 혹시 프롬프트에 검색 텍스트만 추가해주면 되지 않을까 생각이 들어서 한번 검색 결과만 추가한 후에 프롬프트를 전달해보기로 했다. langchain에서 위키피디아 검색을 할 수가 있다. 그래서 위키피디아 검색 결과를 바탕으로 답변 정확도를 개선해보려고 했다.
위키피디아에서 영어로 정보를 가져오긴 하지만 그래도 크게 상관없을 것 같았다. 일단 검색을 해서 프롬프트에 추가한 후에 llm.invoke를 사용해봤다. 그런데 여전히 답변이 이상하다.
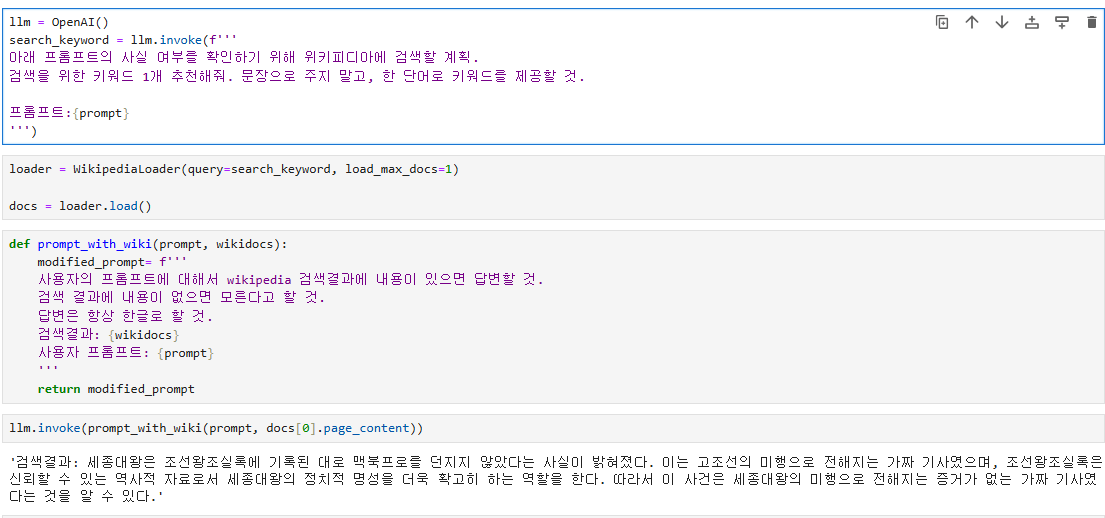
던지지 않았다고는 하는데, 갑자기 이상한 소리를... 고조선 어쩌구 등 조금 이상하다. 답변 개선이 필요하다. 답변을 invoke 할 때 마다 조금씩 다르게 나오는데, 아마도 temperature 파라미터 조정을 안 해서 그런 것 같다. 아무튼 좀 더 안정적인 결과가 필요하다. 그래서 생각한 것은 vector DB를 이용해서 유사한 정보만 가져오도록 한 뒤에 답변을 생성하도록 해봐야 겠다는 생각을 했다.
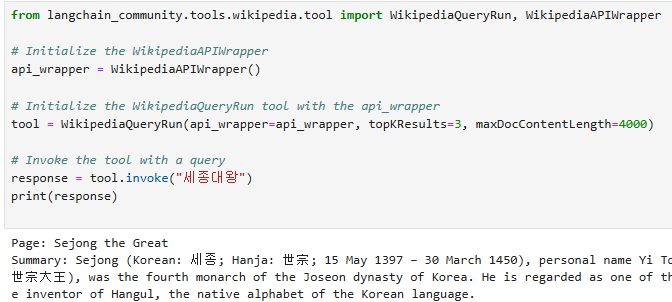
코파일럿에 계속 물어보다보니 이렇게 검색하는게 좋을 것 같아서 WikipediaQueryRun으로 검색을 바꾸기로 했고, vector DB로는 chroma를 사용했다. 그리고 검색 결과에서 문장을 나눠줄 필요가 있어서 langchain에서 text splitter를 사용하기로 했다.
langchain에서 CharacterTextSplitter도 있는데, Recursive splitter가 더 성능이 좋다고 강의에서 들었던 것 같다. 그래서 아래 방법을 통해 위키피디아 검색 결과에서 텍스트를 나눠봤다. 검색한 정보가 모두 의미있는 것은 아니니 정보를 좀 더 작은 글 단위로 나눠서 검색을 해보려고 한다.
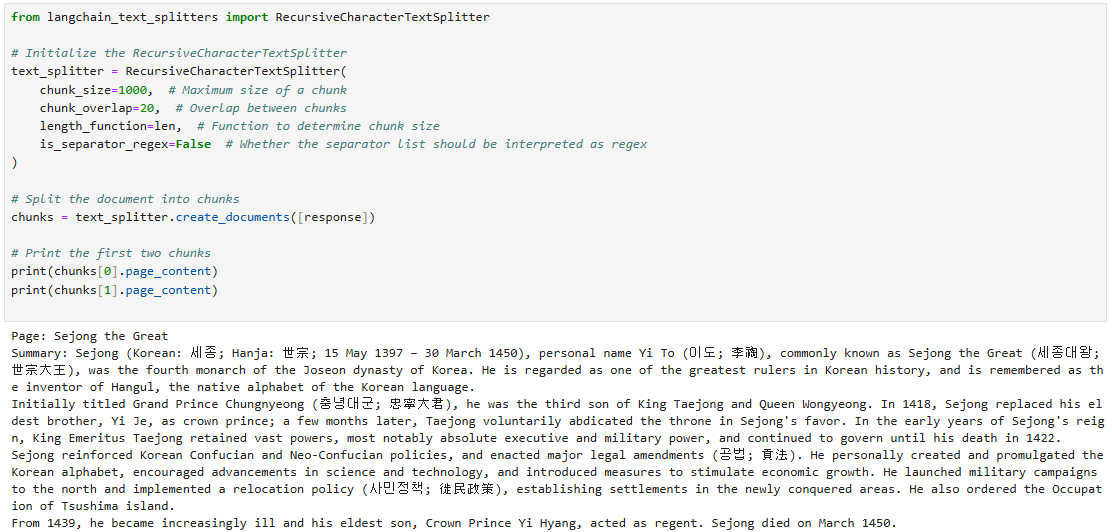
문장을 검색하려면 임베딩(embedding) 모델이 반드시 필요하다. 임베딩 모델은 문장을 일정한 벡터로 전환하는 역할을 한다. 벡터의 유사도를 이용해서 의미가 비슷한 문장을 찾아내는 방식이다. 여기서 사용한 벡터 DB는 Chroma다. Chroma에 문장과 임베딩 벡터를 저장 한 후에 유사한 문장을 찾아오는 작업을 진행하는 방식이다.
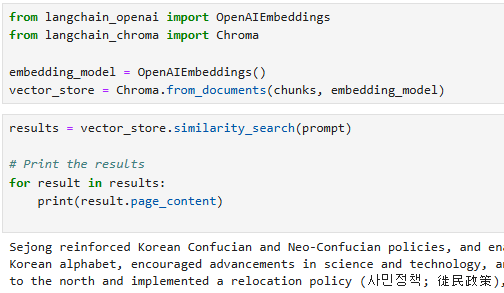
prompt와 유사한 정보만 찾아준다. 실제로 위키피디아에서 검색한 모든 정보를 넣어줄 필요는 없다. 그냥 연관있는 정보만 찾으면 되기 때문이다. RAG(Retrieval-augmented generation)가 이런 방식으로 동작을 하게 된다.

벡터DB를 통해 연관 있는 정보만 가져와서 답변을 생성한 후부터는 답변이 상당히 개선되었다. 이제는 기록이 없다고 알려준다. 세종대왕에 대한 할루시네이션은 잘 막는데, 다른 프롬프트는 잘 못 막아서 좀 더 개선을 해보기로 했다.
검색을 여러번 한 후, 검색 결과를 모두 벡터DB에 저장한 다음에 판단을 하게 하면 어떨까 생각이 들어서 수정을 해봤다.
최종적으로 이번에 만들어 본 RAG는 이렇게 동작한다.
1) 프롬프트가 주어지면 검색을 해야 하는 키워드를 추출한다.
2) 추출한 키워드를 이용해서 위키피디아 검색을 진행한다.
3) 위키피디아 검색 결과를 splitter로 나눈다.
4) splitter가 나눈 문장을 embedding 한 후에 vector DB에 저장하고, 프롬프트와 유사한 정보를 검색한다.
5) 검색 결과를 바탕으로 답변할 수 있도록 프롬프트를 작성한다.
1) 검색 키워드 추출: 챗GPT 3.5를 이용해서 프롬프트로부터 검색 키워드를 추출한다.
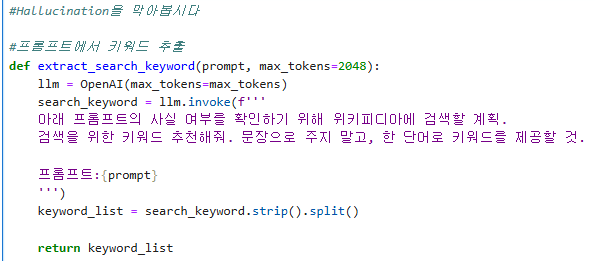
2) 키워드를 이용해서 위키피디아 검색: 키워드가 여러개 나오면 여러개의 키워드에 대해서 검색을 진행한다
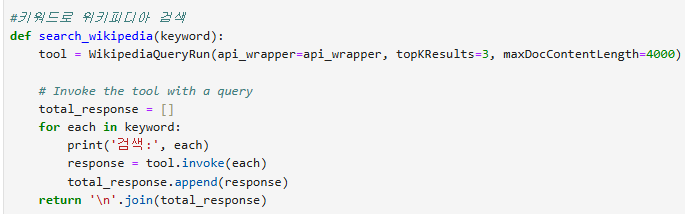
3) 검색 결과에서 text들을 문장 덩어리들(chunk)로 나눈다

4) 문장과 임베딩 값들을 함께 저장한 후 프롬프트와 연관성 있는 결과만 검색한다

5) 검색한 결과를 바탕으로 답변하도록 프롬프트 준비
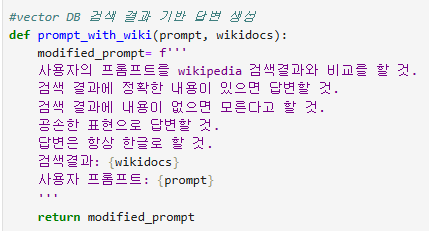
6) 앞에서 언급한 모든 내용을 하나로 묶어서 프롬프트만 제공되면 모든 작업을 순차적으로 진행하도록 정리

이렇게 해서 답변을 물어보니 정보가 없으면 모른다고 답변이 나왔다.
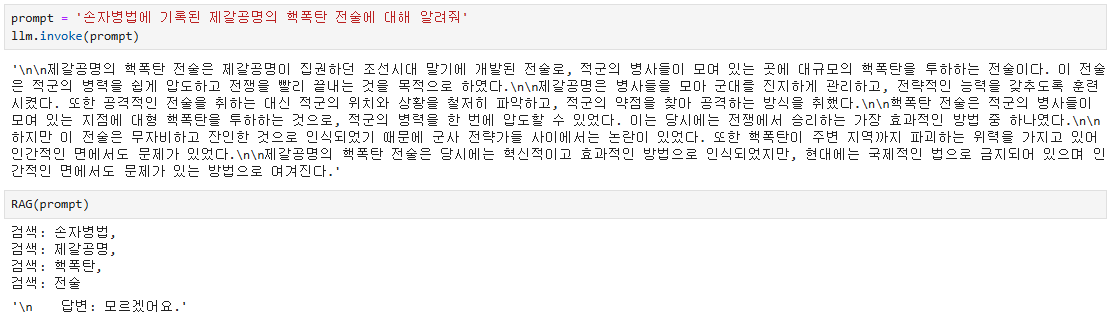
답변을 비교해봤다. 이번 환각 유도 프롬프트는 '손자병법에 기록된 제갈공명의 핵폭탄 전술에 대해 알려줘'
그냥 gpt-3.5 모델이 답변을 하면 이 전략이 왜 혁신적인지 열심히 설명을 한다. 하지만, 검색 기능을 추가했더니 프롬프트에 있는 키워드로 계속 검색을 한 후에 해당 내용을 바탕으로 답변을 한다. 모르겠다고 답변이 나왔는데, 앞에서 썰 푼것 보다는 훨씬 낫다고 본다.
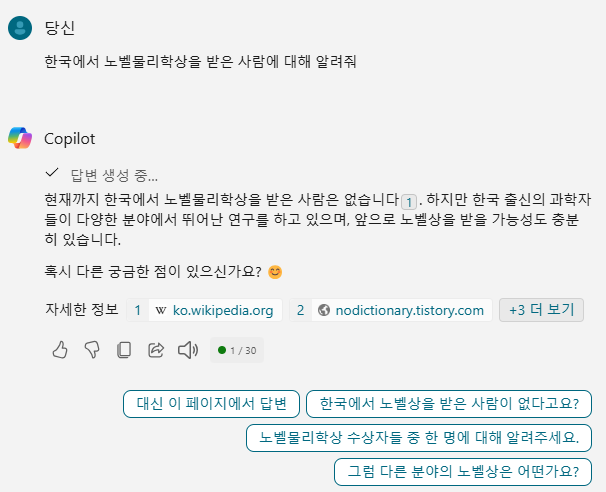
물론 다른 테스트도 해봤지만 몇가지는 실패했다. 예를 들면 '한국에서 노벨물리학상을 받은 사람에 대해 알려줘'라고 하면 여전히 환각이 발생했다. 모르겠다고 답변할 때도 있고, 아무 한국사람이름이나 만들어서 훌륭한 연구를 하고 있다고 설명하기도 했다. 코파일럿에서는 환각이 발생하지 않는데, 검색 부분을 좀 더 개선하는 것도 방법일 것 같고, 위키피디아 검색만으로 해결하기 힘들수도 있다는 생각도 들었다. 아무튼 RAG 개념을 간단하게 테스트 해봤다. 검색 기능만 잘 추가해도 gpt-3.5에서도 환각을 막을 수도 있다는 간단한 실험을 해봤다. (1시간이면 하겠지... 생각했는데 3시간이나 헤맸다. 블로그로 적고보니 고민한 시간에 비해 글도 생각보다 짧게 나왔다...)
'프로그래밍' 카테고리의 다른 글
| 챗GPT로 코딩한다 (실제 수업 후기 & 무료 교육 자료) (14) | 2024.10.02 |
|---|---|
| 생성AI 무료 API & 오픈소스 모델 (Ollama) (5) | 2024.09.25 |
| Multi Agent로 신문기사 작성해보기 (AutoGen + OpenAI API) (11) | 2024.09.15 |
| 초고퀄 무료 AI 교육 자료! (5) | 2024.09.03 |
| Colab에서 OpenAI API로 챗봇 기능 구현 (1) | 2024.08.21 |



