나를 위한 서류 요약 AI 비서를 전문용어로 RAG (Retrieval-augmented generation)라고 한다. 내가 제공한 문서에서 요약도 해주고 필요한 정보도 찾아줄 수 있다. 보안 문제 때문에 공개하기 어려운 서류도 AnythingLLM에 Ollama를 연결해서 사용하면 보안 문제 없이 RAG를 만들 수 있다. 먼저는 ollama를 설치해줘야 한다.
Ollama
Get up and running with large language models.
ollama.com
그리고 나서 AnythingLLM을 설치하면 된다.
처음 실행시키면 어디서 언어 모델 연결할 건지 물어보는데 그때 ollama로 지정해주면 된다. 그러면 ollama에 설티된 언어 모델을 AnythingLLM 안에서 사용할 수 있다. AnythingLLM을 실행시키면 아래와 같이 설명이 나온다. 거대언어 모델 기반 프로그램 답게 대화로 사용 방법을 설명한다.
처음에 해야 할일은 워크스페이스를 만드는 일. 워크스페이스를 만들면 서류를 업로드 할 수 있다. 여기에 서류 업로드하고 임베딩하면 RAG 시스템 구현 완료다. 그래서 설치만 하면 누구나 개인 노트북이나 PC에서 서류를 요약해주는 개인 맞춤형 AI 비서를 바로 만들 수 있다 :)
이 작업에서 가장 오래 걸리는 건 ollama와 anythingLLM 설치. 그리고 ollama에서 언어모델 다운받는 과정인 듯.
워크스페이사 만들기 버튼은 상단 좌측에 있다. 그 버튼을 누르면 워크스페이스가 만들어지고 여기에 서류를 업로드할 수 있는 옵션이 생긴다.
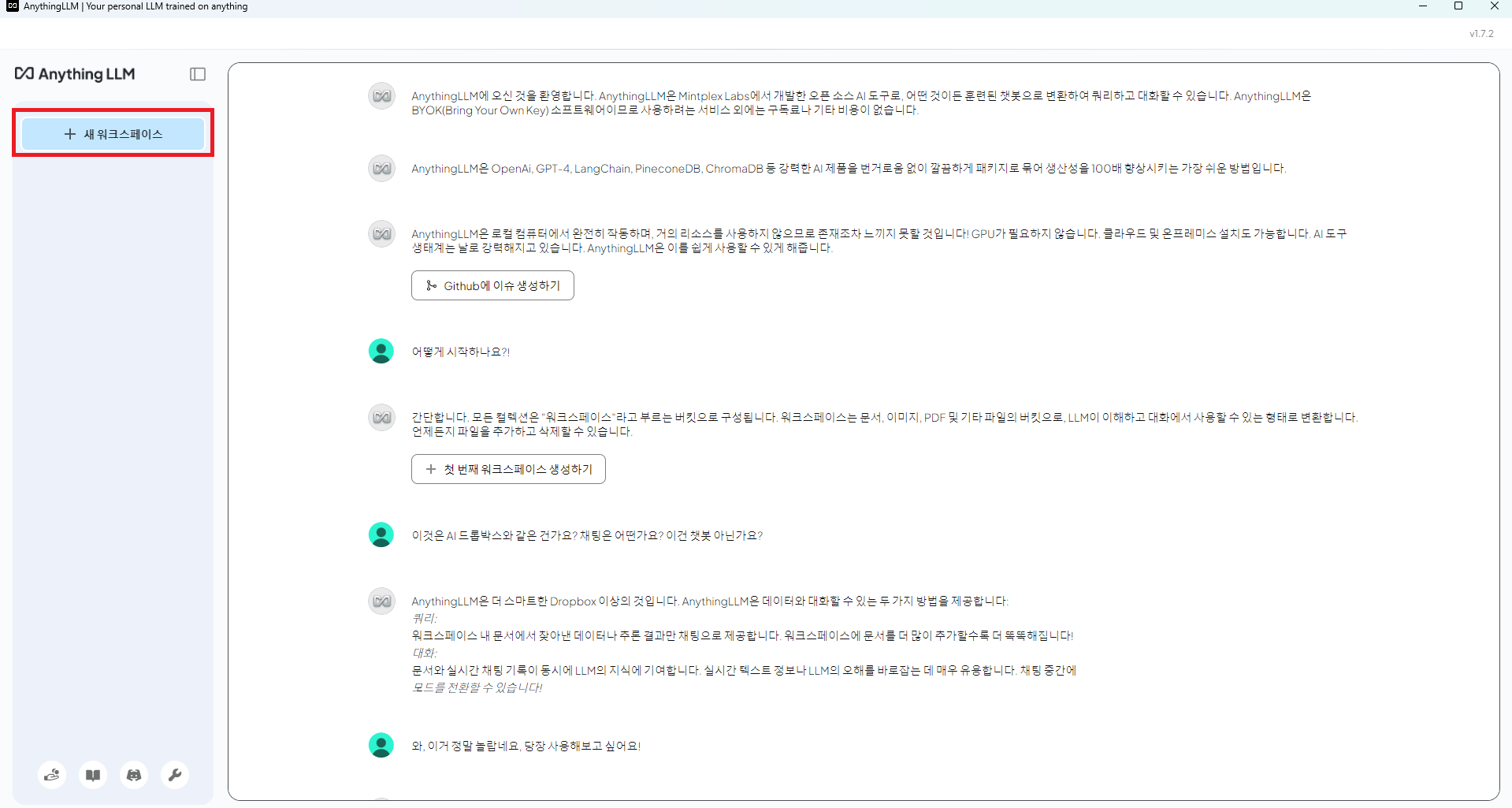
워크스페이스 이름은... 아무거나. 나는 여기서 테스트 용이니 test라고 지었다. 하지만 이름은 기왕이면 의미 있게 짓는것이 좋은 것 같다. 개인적으로 보고서 분석용이었기 때문에 report_chatbot이런 식으로 이름 지어주는 것이 좋다. 왜냐하면 시간 지나면 이게 뭐였는지 기억이 안난다 (...)

만들어진 워크 스페이스에서 서류를 업로드 할 수 있다. 서류 업로드 버튼 옆은 설정 버튼. 여기서 사용하고 싶은 언어 모델을 변경할 수도 있다. ollama에서 설치할 수 있는 모델이 여러개 있으니 테스트해보고 가장 좋은 것을 선택하면 된다. 개인적으로 테스트 해본 모델은 아래와 같다. 파라미터가 적으면서도 성능이 괜찮았던 모델들이다.
알리바바: Qwen2.5
구글: Gemma2
메타: llama3.1~3.3
딥식: deepseek-R1
LG: exaone3.5
마이크로소프트: phi4

임장 보고서 작성하는데 도시기본계획 서류에서 원하는 정보를 찾기 위해 만들었던 RAG. 그냥 읽으려니 보고서 양이 너무 많아서 귀찮았기 때문에 (...)

RAG는 기본적으로 언어모델과 임베딩모델이 필요하다. 임베딩모델은 텍스트를 벡터로 변환시키는 작업을 한다. 그리고 의미가 유사한 텍스트는 유사한 벡터값을 갖게 된다. 내가 챗봇에 질문을 하면, 그 질문도 벡터로 변환된다. 그리고 질문의 벡터값과 유사한 벡터값의 문장들을 찾아낼 수 있다. 임베딩 모델을 통해 사용자가 원하는 정보만 찾아내게 된다. 연관 정보를 찾아오면 이제 언어모델에게 사용자의 질문과 찾아온 문장을 같이 전달해준다. 그러면 좀 더 정확한 답변을 작성할 수 있게 되는 것이다.

약간 시간이 걸리지만, 완료되면 이제 챗봇에서 서류 내용에 기반한 대화를 해볼 수 있다. 아래는 임베딩 진행 중인 화면. 맨 처음에는 이상하게 오래 걸렸었다. 지금 다시 해보니 생각보다 금방 끝남.

언어 모델을 바꾸고 싶다면 설정에 들어가서 변경하면된다. 모델마다 성능이 많이 다름. 그래서 테스트 해보고 가장 좋은 모델을 쓰는 것이 좋다고 본다. 기본세팅은 deepseek-R1으로 되어 있지만 ollama에서 알리바바 모델인 qwen-2.5으로 변경해서 채팅을 해보기로 했다. 참고로 설정을 변경했으면 창 하단에 update workspace 버튼을 꼭 눌러줘야 반영된다.

서류에 대해서 질문 하면 연관 정보를 찾아서 답변을 작성해준다. 답변 하단에는 정보의 출처도 함께 제공해준다. 그래서 답변의 출처(citation)를 통해 답변이 제대로 생성되었는지 평가해볼 수 있다. citation을 눌러보면 문서에서 가져온 문장들만 보인다. 지금 올린 pdf는 표가 많아서 그런지 문장이 많이 깨져있다. 그리고 답변 중에 출처에 없는 정보들도 있다. 그래서 이 답변은 신뢰도가 낮은 것으로 판단 (...) 문서에서 텍스트를 가져오기도 어렵고, 모델 파라미터도 적어서 그런지 성능이 아쉬움.

RAG를 만드는 것 자체는 쉬워졌지만, 답변의 신뢰도를 끌어올리려면 약간 실험은 필요하다. 참고로 RAG는 꼭 문서에서만 찾아올 수 있는 것은 아니다. 다른 정보들도 연동시킬 수 있다. 유튜브 영상과도 대화 가능 :D

'생성AI' 카테고리의 다른 글
| 코드 인터프리터를 무제한으로 사용해보자 (1) | 2025.03.16 |
|---|---|
| 실망스러운 코파일럿 (1) | 2025.03.08 |
| 스타트업과 투자자들이 반드시 사용해야 하는 AI 서비스 TOP5 (2) | 2024.11.26 |
| AI랑 AGI랑 그게 그거 아닌가요? (3) | 2024.11.14 |
| 신입도 단번에 이해시키는 AI 활용 업무 분담 (2 step으로 충분해요) (1) | 2024.10.08 |



